Google Cloud offers two powerful relational database services—Cloud SQL and Cloud Spanner. While both provide fully managed SQL capabilities, they serve very different needs depending on the scale and architecture of your application.

Cloud SQL
Cloud SQL is the fully managed relational database service on Google Cloud. It supports standard database engines including MySQL, PostgreSQL and SQL Server, making it an ideal lift-and-shift target for teams migrating from on-premises or local databases. It supports vertical scaling by increase CPU, memory, or storage resources to handle heavier workloads. For higher availability and durability, it offers automatic replication across zones within a region. The following options helps us to configure the same.
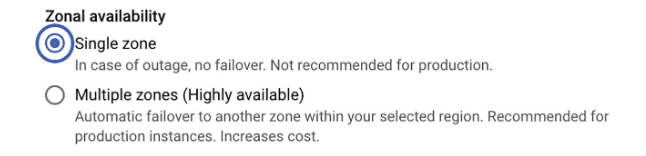
If High Availability is selected, In Google Cloud SQL, a standby instance is a secondary database instance that is automatically maintained to support high availability (HA).
It exists only when you enable High Availability (regional configuration) for a Cloud SQL instance.
How It Works
When High Availability is enabled:
- Google Cloud creates:
- Primary instance (active, serves traffic)
- Standby instance (passive, does NOT serve traffic)
- Both are placed in different zones within the same region
- Data is synchronously replicated from primary to standby
- If the primary fails → automatic failover occurs

⭐ One Main Point to Remember (Exam Tip)
A standby instance is for availability, not for performance.

Cloud Spanner
Cloud Spanner is Google Cloud’s globally distributed, horizontally scalable relational database. Spanner supports global or multi-region deployments — making it ideal for applications with users spread across the world, requiring low-latency access and high availability. This is the main difference with Cloud SQL. Schema changes (e.g., adding columns) can be made online without downtime even while serving traffic.
Don’t think of Cloud Spanner as “Cloud SQL plus more,” but as a different class of database built for global, mission-critical workloads that outgrow traditional engines.
🔍 Quick Comparison
| Feature | Cloud SQL | Cloud Spanner |
|---|---|---|
| Engine Support | MySQL, PostgreSQL, SQL Server | GoogleSQL / PostgreSQL dialect |
| Scaling | Vertical (bigger machines) | Horizontal (more nodes/regions) |
| Distribution | Regional with failover | Global, multi-region replication |
| Consistency | Strong in primary region | Global strong consistency |
| Max Data volume | ~64 TB per instance (varies by engine) | Petabyte-scale, virtually unlimited |
| Best For | Traditional apps, regional workloads | Worldwide apps, high throughput, massive scale |
🟥 Exam Tip
If you are asked to identify a product that offers high availability, global scale, multi-region deployments, and advanced configuration options, confidently choose Cloud Spanner.

Leave a comment